

Mar 10, 2021 Marketing Analytics Methods – Data Technology Needed to Support Multi-Touch Attribution
Multi-Touch Attribution
In previous posts, I have talked about understanding the buyer’s journey on the way to a sale. Marketers need to know which touch points along the journey are most important so they can increase spend on what is working. Multi-Touch Attribution is a marketing analytics statistical method that is used to compute the relative importance of each touch point. My colleague Ed Holmquist is going to post in the weeks to come more about what this is and how it works.
Being someone who has a specialty in complex database design and deep expertise in information technology, I want to focus on the information technology infrastructure needed to support this kind of advanced marketing analytic technique. To map the buyer’s journey, you need to collect all of the digital (and non-digital if you can) touchpoints the customer touches and be able to attribute these to the same customer.
Data Sources and Connectors
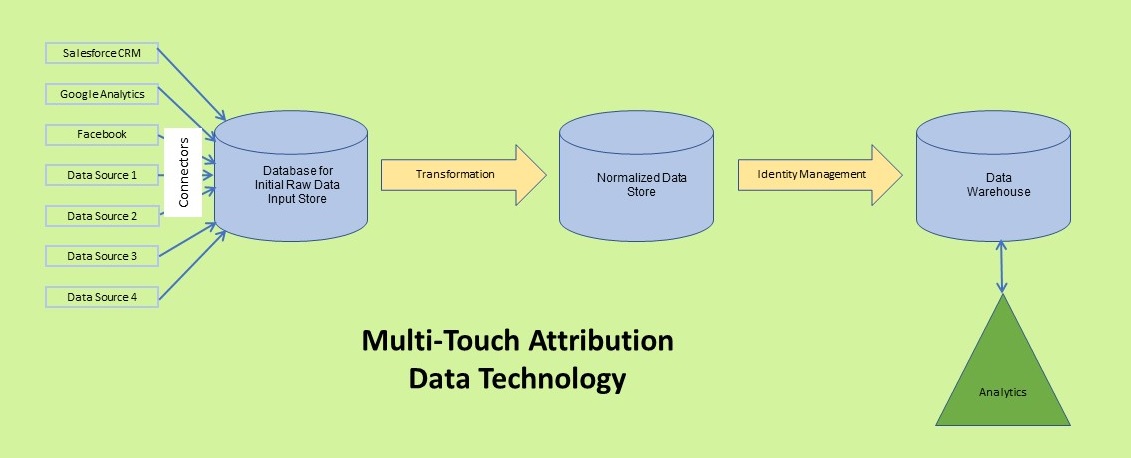
The process starts by building a way to bring all of the data you need to collect from every source (e.g., paid search, website traffic and behavior, white paper downloads, email campaigns, etc.). For a marketer, this is all channels you use for marketing a product and all sources of information (ratings, social media, etc.) your customers might utilize. For Advertising agencies, multiply this by the number of products and clients. This is a lot of data. For optimum marketing spend effectiveness, it needs to be continuously compiled and analyzed in real time.
Fortunately, there are a number of vendors that make data connectors available to a large number of standard sources of information (e.g., Google Analytics, Facebook, etc.). Unfortunately, they vary greatly in ease of configuration, reliability, price and ability to absorb data structure changes.
Loading the Data Warehouse-ETL vs. ELT
Next you need a place to house all this data. The industry jargon is data lake or data warehouse or data mart but really these are different approaches to a big database or set of databases. Each source has a different data structure, so this adds to the complexity. You also need to decide whether the first stop will be raw data or transformed data. Again, the industry jargon talks about whether you are going to extract the data, then transform it and then load it (ETL) or extract the data, load it and then transform it (ELT). I have a strong preference for ELT because it allows the marketer or agency to keep the connectors as stable as possible. In addition, changes in needs can be accommodated without any re-integration with the sending source. By change in needs, I am talking about deciding on a new type of analysis or another way of looking at the data. In ELT, you just change your transformation which is completely under your control. Re-integrations are painful, time consuming and expensive because you have to get the attention of the source folks, agree on the changes, make the programming changes, test it collectively between teams, etc. It’s a big deal.
Customer Identity Management
For use in multi-touch attribution, once you get the data in your database, you need a way to uniquely match all the data for each person across sources. In the jargon, this is identity management. At its essence, your objective is to create a master record for each person that contains all the known information about that person. This will include the person’s name, address, personal and work phones, personal and work emails, etc. Subtle changes in spelling, address versions (street vs St, with or without apartment number) and so on have to be screened and combined. When you get an interaction at a touch point, you then look at what you know from the interaction and try to map it to someone in your set of master records. You not only need to then tag that information with a unique internal identifier so you can use it in your analysis, you need to constantly evolve the data in the master record with each piece of new information. You need to be able to differentiate people at the same address and household. If using this data for personalization of communication, you need the context to be able to contact that person on a work email for work stuff and on a personal email for personal stuff. Take my word for it, this is hard. Again, you can program it yourself on get help from a few vendors.
Usable Data to Support Multi-Touch Marketing Analytics
Finally, you need to set the data up for applying the complex statistical computations necessary. This may require queries across unlike data sets. In the industry jargon, this means structured and unstructured data (SQL and NoSQL) and text, images, etc. These queries can be across not only different structures/toolsets, but each database can be in different physical locations and vendors (think Amazon Web Services, Google, etc.). When you run the complex computations, all of the compute factors have to be scaled and capable of handling huge amounts of data so that the above factors can be computed across people and touchpoints. In a gross simplification, you can think about the data as a giant spreadsheet where the columns are individual touchpoints, and the rows are different people. Since people have different buyer journeys, many cells will not be filled in for all the possible touchpoints for each person (and journey for that matter). Then the statistical techniques underpinning multi-touch attribution are applied to the data in a column (as part of a complex multi-step process) to compute is weight or contribution to the buying process.
Technology Guidance
One of the major complexities around creating the data technology needed for advanced marketing analytics, is deciding which combination of tools is matched to your company’s capabilities and needs, your budget, and your timeframe. It is also that many vendors want to get your data into their own proprietary environment so they can get the biggest piece of your budget. In theory, each vendor has optimized their components to best accomplish what they do, but this is not always true. Having your data in these proprietary environments can make integration with subsequent steps in the process complex and also result in duplicate data all over the place which makes control of the whole process difficult. So, while all vendors may claim they will play nice with the other children (vendors), in practice this often creates more complications.
If you are still reading this, I am sure you have already concluded that it is likely not a process you want to take forward on your own. We are here to help.
Bryan B Mason
Apollo Consulting Group, Newport, RI
No Comments